When a user chooses to archive old backups to S3 in the backup job settings, it means that old backups that do not comply with retention policy settings will be copied to a special S3 bucket created by CDSB. This feature is available for both instances and standalone volumes.
1.An S3 bucket is created by CDSB automatically as soon as there is a need to place backups into it.
2.The name of the S3 bucket is “cdsb-<bucket ID>”. The Bucket ID is a unique key formed by the current AWS account and region.
3.The S3 bucket has the following structure:
ovol-<volume ID>
✍metadata
✍backups
•backup ID
ometadata
oblockdata
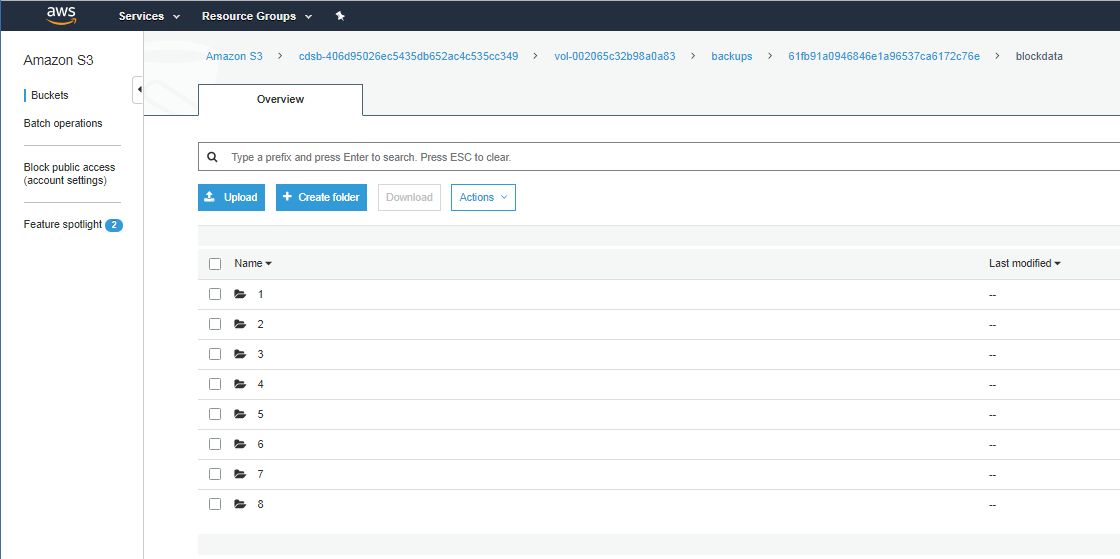
4.Backups of every volume are stored in a separate folder named as vol-<volume ID>.
5.The first backup of every volume is a full backup and the subsequent backups are incremental and store just changed blocks data.
6.For every volume in a backup job CDBS starts a temporary worker instance, which is responsible for copying data from this volume to S3. After the data is copied, a worker instance is terminated by CDSB.
7.A special lifecycle rule is automatically created for the CDSB bucket that regulates the transition of S3 bucket data to Amazon S3 Glacier.
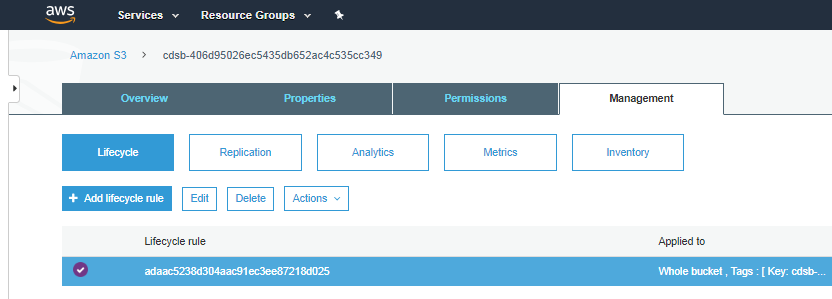
By default, block data is copied to Amazon S3 Glacier immediately, metadata is not copied to Glacier under any circumstances.
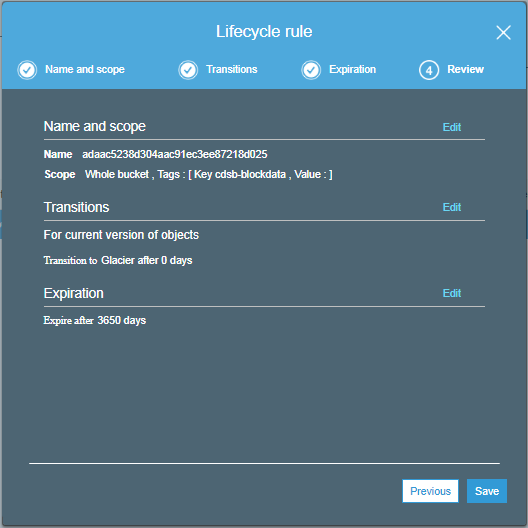
You can change these settings if needed.
Backups that are stored in the Amazon S3 Glacier bucket are marked as archived in the Backups listing, as shown below.
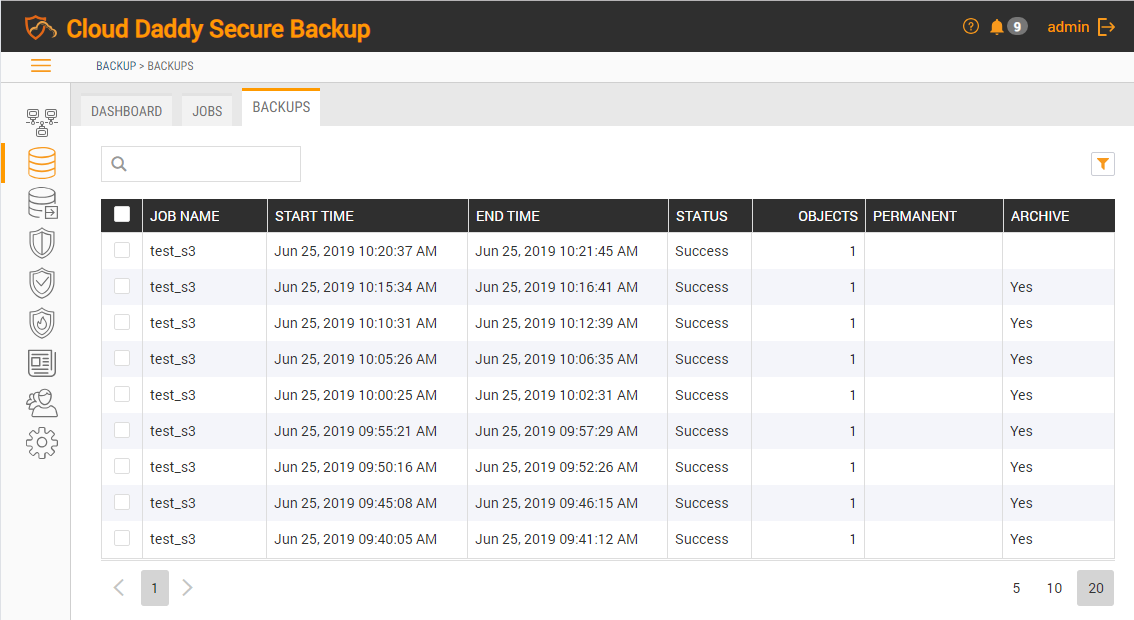
The restore from archived backups can take a lot longer than restore from a backup based on an EC2 snapshot, especially if it was moved to Amazon S3 Glacier. Therefore, it is recommended to set a balance between storage price and recovery time.